Error Handling part 2: Abstractions
In previous post, we defined an error as a broken assumption, then split those into unexpected errors and expected errors. Eventually, we outlined a decision process, leaving some crucial questions unanswered, namely:
- What exactly makes an error recoverable?
- What is meant by exposing internals?
We said the key to answering those is keeping levels of abstraction consistent, and that is the subject of this post.
Levels of abstraction
A level of abstraction is a consistent view of a set of related concepts or components of an application. We decompose that view into contracts that specify what each part does and what it requires. In software design, those contracts are usually formalized as interfaces.
Until it fails
Abstractions hide the innards of components, allowing separation of concerns and interoperability. That is, they enable reasoning about and re-using components as black‑boxes, not caring about their working details.
For instance an http module might provide an abstraction of connecting to webservers to download documents and all of a sudden, we can “fetch-that-url” and not worry about how the fetching works.
http_fetch(
url) →bytes
Retrieve a document over HTTP.
- Arguments
url: address of document to retrieve.
- Returns
Document content as a
bytesobject.
We might say we lie on top of that abstraction layer.
Underneath, that http module probably only implements the logic that deals with the HTTP protocol itself. For the actual sending and receiving of data, it will rely on other abstraction layers down the line. Maybe some encryption layer for SSL, some connection pooling layer, a low-level networking layer, …
Thus we compose our applications by stacking and juxtaposing abstraction layers, iteratively decomposing our use case until we have all the details sorted out, or composing increasingly complex features until we can answer our use case. As long as we keep those abstraction layers isolated from each other, communicating only though their interfaces, everything is fine.
Until it fails.
Say the encryption layer in our example above fails to fulfill its contract because the peer rejected our certificate. What now?

Errors are part of abstraction
The answers lie in our design. When we model our layers of abstraction, we define interfaces that formalize what our components can do and what they require.
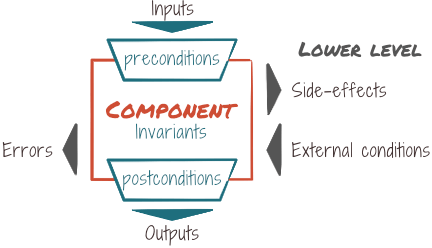
Excluding straight bugs, this implicitly creates two realms for errors:
- Preconditions violations
The client/caller of the component fails to meet the requirements (eg: it provides an invalid URL).
- Failures
Our component fails to fulfill its contract, either by failing to produce side-effects, or by failing to reach postconditions. At this stage, this is usually because of external conditions (eg: network is down).
Preconditions violations are easy. The interface must simply state either that:
-
this is forbidden and such program is ill-formed (ie: this is a bug). Which means this is unexpected error territory.
def http_fetch(url): # force crash on interface violation assert is_valid_url(url) -
or this is an expected error that will get reported. The interface then defines how. In this example, it generates a python
ValueErrorexception.def http_fetch(url): if not is_valid_url(url): raise ValueError("invalid url")
Mixing is possible: for instance the interface could define that passing an improper
url type (eg: a number instead of a string) is a bug, while passing a string that
holds an invalid url generates an error.
Interesting errors are those belonging to the latter realm: the component we are designing fails to fulfill its contract.
We must define this failure. As software designer, our job is to create a language. We define interfaces, which are somewhat like things, bearing nouns: HTTPConnector, CookieJar, etc. And we define tasks, which are somewhat like verbs: fetchDocument, saveCookies, etc.
As we do so, we pick the correct granularity, giving power and flexibility but not so much that simple tasks become a chore. Identifying all relevant interfaces, grouping or splitting them correctly, and differentiating between implementation details we hide and features we expose is an art.
And that art applies to errors as well: it is our job as a designer to:
- identify all possible reasons the component could fail to fulfill its contract for.
- group them into error families that make sense being handled together, possibly hierachizing them for more complex abstractions.
- encapsulate implementation details, ensuring errors do not expose the internals we hid when we designed our interfaces.
Together, those tasks create a language of errors.
Speaking in errors
A level-by-level process
An interesting consequence is that this language is specific to the abstraction layer we are designing. This means that:
-
what is an error at a level of abstraction might not be at levels above.
The upper layer might expect that error and have a recovery process in place. For instance, the interface specification ofhttp_fetchfunction above might define that failure to connect shall be resolved by falling back to a cached copy. Thus, a connection error does not necessarily imply anhttp_fetcherror.Hey, we just answered our first question:
- What makes an error recoverable?
➥ An error is recoverable, at a specific level of abstraction, if and only if that level defines a recovery process for that error.
- what is an error at a level of abstraction might not be at levels below.
For example, a low-level network layer cares about transporting messages from and end to the other end. At the level, messages getting across are not an error. However, one of those messages could contain some HTTP error response, that will be interpreted as an error by the HTTP layer above.
This is why error handling focuses a lot on abstraction boundaries: different abstraction layers speak a different error language, so translation should happen when crossing boundaries.
Translating errors
Summarizing our thoughts so far:
- What is meant by exposing internals?
➥ Errors are part of abstraction.
➥ The purpose of abstractions is to encapsulate and hide details.
➥ As a part of abstraction, errors contribute to encapsulation.
In particular, when an error cannot be recovered from at a specific level of abstraction, we still must ensure encapsulation is not broken. We do this by translating from lower-level error language to the error language of current level. That is, we convert the error.
Namely, proper error conversion should:
- pick an error appropriate to our level of abstraction.
- remove details from lower-level abstraction that are no longer relevant.
- add context that the lower-level abstraction did not know of.
For instance, assuming we designed our interface as a very simplistic one, hiding SSL usage,
and we grouped all transfer-related errors under a generic TransferError, we could write:
try:
connection.do_handshake()
except SSLError as exc:
raise TransferError(
f"Handshake error while loading ${url} "
f"with connection ${connection_id}: ${exc}",
url=url
) from excOur interface encapsulates the use of SSL as an implementation detail, therefore we cannot
let an SSLError propagate.
We thus change the error type to one of those that client
code can expect from us. We don't forward working details of SSL handshake, but we add
the url as a context field, and ensure that, should the error be logged at some point,
the log will include the connection id.
We also use python error chaining
from
clause to ensure discarded details will be available for error investigation.
The handling of those discarded parts needs special care because,
even though it's not relevant up the abstraction stack, they might be useful for debugging.
Conclusion
A word about functions
As we close this part on levels of abstraction, we should note that at the smallest scope, even a single function:
- encapsulates a task, giving it a name and therefore defining vocabulary.
- has preconditions: predicates that must be true at beginning of the function.
- has postconditions: predicates that must be true at the end of the function.
In fact, every function is an abstraction. And the principles we covered so far apply to functions just as well as they apply to components.
That was longer than I expected. Enough theory, in the next post we will see actual error handling mechanisms in code.
