Error Handling part 1: Introduction
Error handling is a recurrent issue in beginners' and not-so-beginners' code. It is often an afterthought. The typical flow goes like this:
- Get the main functionnality working.
- Realize that edge cases and anything unexpected crashes and burns.
- Add some band-aid where it hurts the most.
In this article series, we will cover the basics of error handling and how it relates to proper abstraction levels for building robust software.
A short typology of errors
An error is a normal and regular event during the life of most programs. It happens whenever an assumption it made turns out to be wrong. For instance, it tried to open a file, but the file does not exist, or it sends data to a remote server, but the laptop has lost Wifi signal.
We can split errors on whether the condition that is not met is expected to happen.
Unexpected errors
Ooops, did not think it could happen!
Whenever an assumption made by a piece of code turns out to be wrong and the developer did not anticipate it could, it is an unexpected error. The program can react in one of two ways:
Undetected, unexpected error
The progam is oblivious and keeps going. This is the most problematic case.

If an assumption turns out to be wrong, it means the program is in a state it was not intended to be in, ever. Therefore, the basis upon which its logic is built is no longer correct. Which means its result is very likely to be incorrect, too.
With unexpected state come unexpected consequences.
As we do not want unexpected consequences, we must detect unexpected state as soon as it happens. To that effect, we must make our expectations explicit, so that the failure is detected.
Detected, unexpected error
An assumption unexpectedly turns out to be wrong. Fortunately, the assumption was made explicit, so the program crashes immediately.
class SavingsAccount:
def withdraw(self, amount):
assert self.balance >= 0
# proceed with withdrawalIn this example, we have a savings account. Its balance cannot, by definition, be negative.
In more formal wording, this is an invariant of class SavingsAccount.
By making this assumption explicit, we will trigger an immediate crash should self.balance
be negative.
“But data will be lost.”
If we reach a point where we have in our system a savings account with negative balance, something has already gone horribly wrong and our data is already corrupted. We want our program to crash and we want it to crash now:
- It prevents contagion. Once the program's assumptions are incorrect, its state is no longer under control, so its behavior is no longer under control. It might corrupt more data. It might overwrite good data with invalid state. It might send invalid data to other components.
- It ensures the failure is noticed. An exception can be silenced. An error can be ignored. Who knows how long it will take until someone notices?
- It helps fixing the code. The longer the program runs after the initial divergence, the harder time we will have locating the faulty code.
It is better to crash quickly and cleanly than to loose more data.
The implication of assertions is that such an error cannot be recovered from, it is a defect in the program, that must be fixed by a person.
Expected errors
When we anticipate the possibility than one of our assumptions might be wrong in an otherwise correct program, and we know a way to deal with it properly, we have an expected error.
Expected errors normally happen at the boundaries of interfaces, where a component talks to another component. This could be, another part of the program, the operating system, a remote server or some hardware component.
def load_settings(path):
with open(path) as fd:
settings = json.load(fd)
return settingsThis example makes many assumptions:
pathcontains a valid file path.- that file path actually names an existing file.
- the program is allowed to open the file.
- the file contains a valid JSON document.
- no resource is exhausted in the process of reading and parsing the file.
We notice those assumptions depend on external concepts and entities. Which means we should reasonably expect them to fail in perfectly valid circumstances, and this should be handled gracefully. Depending on the context and specific error, this can mean:
- Recovering
Our code runs an alternate logic path to reach requested behavior. For instance, here, if opening the file fails, it could fall back to default settings.
def load_settings(path): try: with open(path) as fd: return json.load(fd) except (OSError, JSONDecodeError): # we target specific errors return DEFAULT_SETTINGS- Propagating the error
If our code is unable to handle the error condition at this level, it can propagate it to a higher level, which will then choose how to handle it best. Possibly, such an error can propagate all the way to program entry point and terminate the program.
This is default behavior of python exceptions, so our code in Fig. 3 does this.
- Converting the error
The error as it arises in our code might not be meaningful outside of it. It might pertain to an implementation detail that should not be exposed.
For instance, our
load_settingsfunction is meant to encapsulate the details of settings loading. We usejson.load, which will generate aJSONDecodeErrorif the document is invalid. If we propagated this error to callers, we would expose internal details to them, breaking the encapsulation. To avoid this, ourload_settingsfunction should convert the error into another error, using higher-level semantics.def load_settings(path): try: with open(path) as fd: return json.load(fd) except JSONDecodeError as err: raise ConfigurationError('User mistake in settings') from err
Errors Summary
So you are standing in front of a piece of code, evaluating it line after line, statement after statement. For each and every expectations that it makes, the following diagram should help picking the appropriate action:
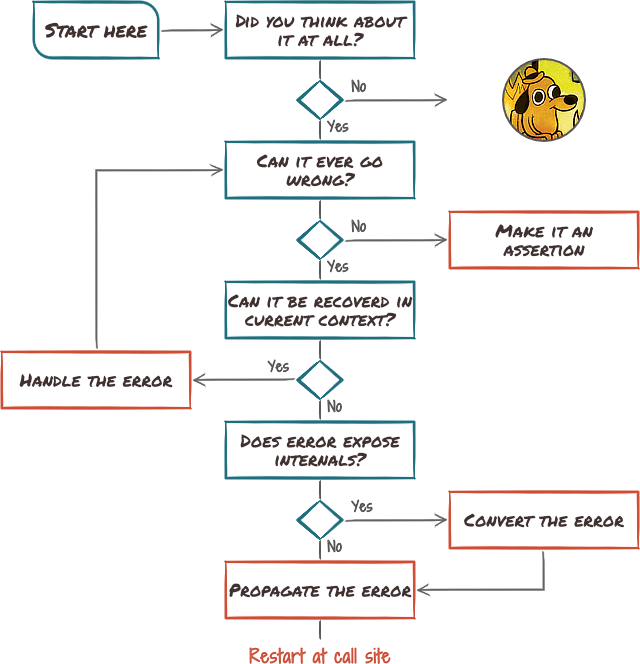
This whole decision happens within one single function, on every expectation it makes. One key part is the final step, at the very bottom: as soon as we propagate an error, we must ensure it is properly handled one level higher up the chain of callers. And then at the next level, and the next level, until either it is recovered from or it reaches the top of the chain, at which point the supporting environment will usually invoke its default handlers, typically printing an error and terminating the program.
We take note, however, that though we outlined the decision process, we have not answered two crucial questions:
- What exactly makes an error recoverable?
- What is meant by exposing internals?
The key to answering those is keeping levels of abstraction consistent. That will be the focus of the next post in this error handling series.
